
The No BS Guide to Build a Context Graph
Jan 26, 2026
Jaya Gupta and Ashu Garg’s recent piece on context graphs went viral for good reason. The core thesis that the next wave of enterprise platforms will capture decision traces, not just data, struck a nerve because it names something real.
The follow-on discourse has done important work: “learned ontologies,” “organizational world models,” “agent trajectories as training signal.” These are the right conceptual frames. What’s been missing is the implementation guide. How do you actually build one?
We built one. Not as a research project. Not as a thought experiment. As infrastructure running in production, powering real customer workflows.
This is that guide.
How We Got Here (Honestly)
We started building an AI-native CRM. The pitch was simple: auto-updating CRM. We parse your emails, call transcripts, meetings on calendar, Slack messages, etc. etc. and use that to update the CRM fields, pipeline stage and tasks automatically. No more sales reps spending 3 hours a day typing into Salesforce/HubSpot/SAP (jk, we didn’t serve SAP customers. we only serve where hope still exists).
Adoption was slow. Turns out, divorce is easier than switching your CRM (shocker 🙄).
But ENGAGEMENT WAS SURPRISINGLY HIGH! 🤯
Users kept coming back for one thing: seeing what was happening with customers across their organization in a single place. Context they couldn’t query anywhere else.
“I can finally see what my colleague (or an opaque department: looking at ye LEGAL) discussed with this customer last month.”
“I didn’t have to dig through Slack threads to understand this deal.”
This wasn’t one customer. It was ALL OF THEM.
So we followed the pull. We stopped being a CRM with good context and started being context infrastructure that could power any customer workflow.
Then organizations started asking for RULES!
“Can we add our sales playbook as context?”
“Can the AI run our BDR assignment logic?”
“We have canned responses for support. Can the AI use those to understand how we answer specific cases?”
So we started building a rules engine.
But here’s what we kept noticing: most of the patterns that matter aren’t written down.
When your top AE knows to loop in the VP of Sales for any deal over $100K with a new logo in financial services, that’s not in the playbook. When your support lead knows that enterprise customers who contact you three times in a week are about to churn, that’s not in the escalation policy. It’s in their heads.
That’s what we’re building now: infrastructure that captures these unwritten patterns as they happen, learns from them, and surfaces them when they’re relevant again.
Our Context Workflow: Ingestion to Retrieval
Here’s how context actually flows through our system.
Step 1: Ingestion
Raw data flows in from connected sources: email, calendar, CRM, call recordings, Slack.
A Gong recording lands. Transcript mentions “Acme,” “Sarah from procurement,” “Q4 budget deadline,” “John promoted to VP of Sales” and “concerned about Competitor X.”
Step 2: Entity Extraction & Resolution
We extract identity signals (email addresses, company names, domains, job titles) and resolve entities against what we already know. New entities get created when signals don’t match; known entities get their context updated.
Email domain matches existing Acme Corp account. Sarah Chen created as new contact. Insights generated: “Competitor X mentioned in evaluation,” “Q4 budget deadline discussed,” “Procurement is now engaged.”
See how this works in our Slack integration in Nex.ai
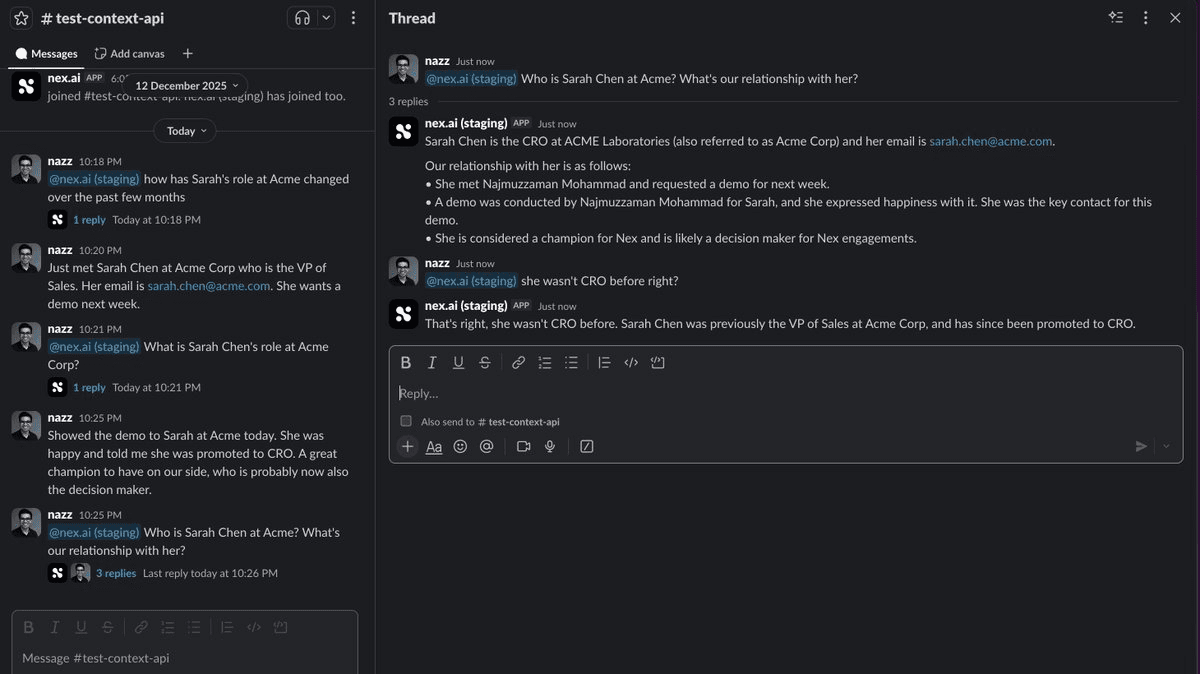
Nex.ai Slack integration. You gotta click this picture and Zoom it to read.
Step 3: Context Synthesis
Raw extractions become structured knowledge: discrete insights with temporal validity, superseding chains, and relationships.
Every piece of content gets processed into discrete, single-thread insights, individually updateable facts. When John’s objection shifts from “integration timeline” to “budget approval,” we update that specific insight while preserving the rest. Each insight carries temporal metadata and supersedes rather than deletes, so you can ask “What were John’s objections three months ago?”
Acme Corp context now includes: “Procurement engaged as of Nov 12. Q4 budget deadline mentioned. Competitor X in evaluation. John’s role changed from Sales Manager to VP of Sales"

DB entry showing a sample superseded insight
Step 4: Heuristics Extraction
As traces accumulate, the system clusters semantically similar situations and extracts organizational heuristics. This runs periodically in the background.
We don’t define signals upfront. Entity insights get embedded into vectors, clustered by similarity, and centroids become pattern embeddings. An LLM generates human-readable pattern names from representative samples in each cluster.
After a few days, clustering reveals:
67 situations: Enterprise deals stuck in negotiation, multiple stakeholders, no executive engaged → “Multi-Stakeholder Stall”
43 situations: Competitor actively in evaluation, feature comparisons → “Competitor Displacement”
38 situations: Q4 enterprise new-logo, procurement pressure → “Q4 Budget Rush”
Scattered Tuesday interactions → No pattern (noise)
See how we show this in the Nex.ai chat today.
(Don't worry. This is mock data but still based on a real customer we are helping provide context for support agents)

Recommendations from organizational heuristics
Step 5: Query + Pattern Matching
When someone asks the AI a question:
Retrieve relevant entity context
Embed the current situation
Vector-search for semantically similar patterns
Inject applicable heuristics into the AI’s context
AE asks: “What’s the risk on Acme and how do I close this by end of quarter?”Current context embedded. Patterns matched via similarity: Multi-Stakeholder Stall (0.84), Competitor Displacement (0.79), Q4 Budget Rush (0.76)

Step 6: AI Response with Organizational Intelligence
The AI responds with learned patterns baked in. Not just what it knows about Acme, but what the organization has learned from similar situations.
“Three risk factors on Acme: (1) You have 4 stakeholders but no executive sponsor. Deals with this profile that added VP alignment closed 2.3x more often. (2) Competitor X is in the mix. Your win rate against them improves 40% when you lead with integration speed. (3) Q4 enterprise deals need MSA started by week 2 of December to clear procurement.”
This is the moment users go “oh, that’s actually useful” instead of “that’s a nice summary of what I already knew.”

Step 7: Trace Capture
The decision context gets captured as a trace: entities involved, context present, patterns that matched, the response given.
Trace captured. This becomes evidence for the patterns that matched. If the deal closes, patterns get reinforced. If it doesn’t, the system learns that too.
(We store traces as metadata on the decision records themselves, not a separate database. When you look at an AI response, you see the trace that explains it. When you delete an interaction, the trace goes with it. No orphans.)
Step 8: Pattern Evolution
Patterns refine as traces accumulate. New patterns emerge. Existing patterns split when the system detects subgroups.
“Multi-Stakeholder Stall” splits into “New Logo” and “Expansion” variants. Different playbooks for each.
Patterns evolve continuously based on new traces and feedback. When an AE marks a suggestion as helpful, that’s signal. When they ignore it, that’s signal too.
The Hard Parts
Learned patterns will sometimes be wrong
You can’t capture every signal that contributes to decision-making. Some signals are offline (hallway conversations, gut feelings). Some are in systems you’ll never integrate. Some are simply ineffable.
So we made patterns visible (every response shows which patterns matched and why), tameable (orgs can adjust or disable patterns that don’t fit), and extensible (explicit playbooks run alongside learned patterns).
Authored rules are your floor. Learned patterns capture the edge cases your playbook never anticipated.
Context management: when playbooks go stale
Organizations inject authored context: sales playbooks, escalation policies. But these go stale. The playbook says one thing, but decisions in Slack three months ago updated the approach.
If the AI surfaces outdated recommendations, or worse, automatically updates the playbook based on incomplete context, you’ve corrupted organizational knowledge.
What’s needed: The ability to lock certain context, recommendations on updates that humans review before applying, and provenance tracking. We’re actively building this.
(the big one) Permissioning learned knowledge
Permission systems exist for data. Who can see this document. But learned knowledge is different: patterns extracted from decisions across content that different people have different access to.
Imagine a pattern learned from 40 deals. A junior AE has access to some of those deals, not others. Should they see the pattern? It doesn’t expose confidential data directly, but it was learned from it.
Think about how a senior employee handles this. They might give the answer without explanation, give partial context, give full context, or decline to help, depending on clearance and judgment. This selective exposure is what we need to model.
We don’t have complete answers. Permission for context is fundamentally different from permission for data. If you’ve solved this, comment below.
What’s Next
The current system captures traces, extracts patterns, and surfaces heuristics. What comes next:
Outcome tracking
“Of 67 deals where this pattern was surfaced and the rep added executive alignment, 58% closed. Of 23 where they didn’t, 31% closed.” This moves from “this pattern appeared often” to “this pattern actually works.”
Pattern composition
Instead of separate patterns for “enterprise + stalled” and “competitor + stalled” and “Q4 + stalled”, a composed pattern that captures the nuance.
Cross-org learning
If we can learn from anonymized patterns across hundreds of organizations, we can bootstrap new customers with industry-specific heuristics on day one.
The Takeaway
The implementation is less magical than the discourse suggests:
Entity context = resolution + synthesis across fragmented sources
Decision traces = metadata on decisions, capturing context at decision time
Patterns = clusters of similar situations, discovered from embedding similarity
Surfacing = semantic matching. New situations find similar past patterns
The hard part isn’t the infrastructure. It’s context richness (what to capture), cold start (bootstrapping patterns), and integration (getting heuristics into the workflow where decisions happen).
The system that learns how your organization makes decisions, and surfaces that knowledge when it’s needed, compounds over time. That’s the moat.